
HiPR: Fast Incremental Custom Partial Reconfiguration for HLS Developers
Published in The 2022 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2022
Publicated in ACM Digital Library
Recommended citation: Yuanlong Xiao. Andre DeHon. “HiPR: Fast Incremental Custom Partial Reconfiguration for HLS Developers” The 2022 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays(FPGA ’22)..
Abstract
FPGA accelerators have drastically changed application develop- ment as they allow users to exploit arbitrary custom hardware architecture with low Non-Recurring Engineering (NRE) cost. De- spite the significant absolute performance and energy efficiency compared with CPUs, FPGA development requires high levels of hardware expertise and programming skills to unleash the poten- tial parallelism. High-Level Synthesis can abstract away low-level circuits design and improve the coding productivity. However, this also lengthens the compilation time, exacerbating an already slow edit-compile-debug loop that discourages the development and re- finement of FPGA accelerators. Partial Reconfiguration techniques can decrease the compilation time by reducing and parallelizing the size of the compilation task. But defining partial reconfigurable regions also needs expert layout-level knowledge, making this ap- proach inaccessible to the high-level developers that HLS is in- tended to attract. To address the problems above, we propose HiPR, an open-source framework that bridges the gap between HLS and PR. With HiPR, users can define a C/C++ function (rather than a Verilog module) as partially reconfigurable without considering detailed low-level constraints. HiPR automates the PR floorplan and allows the users to define elastic resource requirements for the C-level PR function for quick further tuning later. By mapping the full set of Rosetta Benchmarks, we show HiPR can find the proper floorplan solution within seconds and generate the overlay for later tuning. Significantly, the incremental compilation time can be accelerated by 3–10X with no performance loss.
Motivation
For normal Xilinx Vitis flow, Synthesis usually takes more time for the initial compilation (green blocks) as more peripheral modules are only compiled once. By re-saving one source file and recompiling the benchmarks, we only see 21-36 % reduction in compile times, even when we make no modifications to the code in the file.
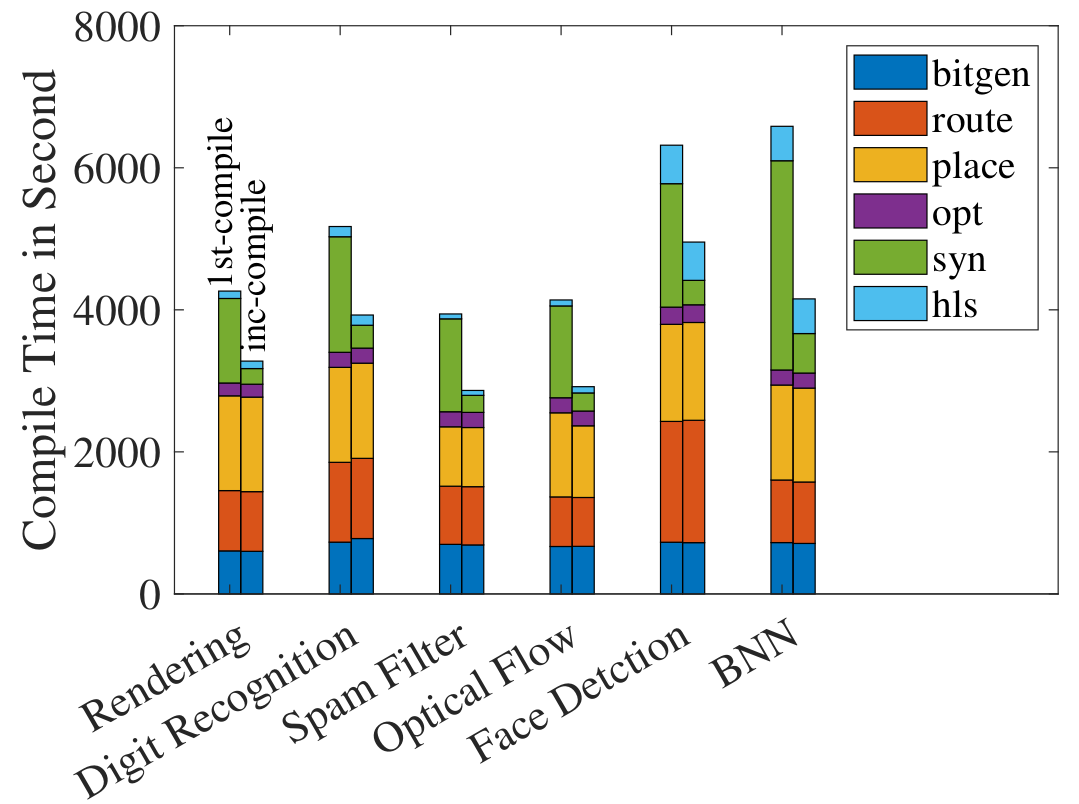
We raise the key question here: Can we compile the HLS source code incrementally, like software, such that we only need to perform placement and routing on the portions of the design that changes?
Compute Model
HiPR uses a dataflow computational graph model based on Kahn Processing Networks (KPN) [15, 18]. Each kernel is describe in C program called operator. The operator receives inputs and sends outputs through latency-insensitive protocols. Different kernels are connected by latency-insensitive interfaces [10], which can be mapped to FIFO or handshake Relay Station [6, 36].
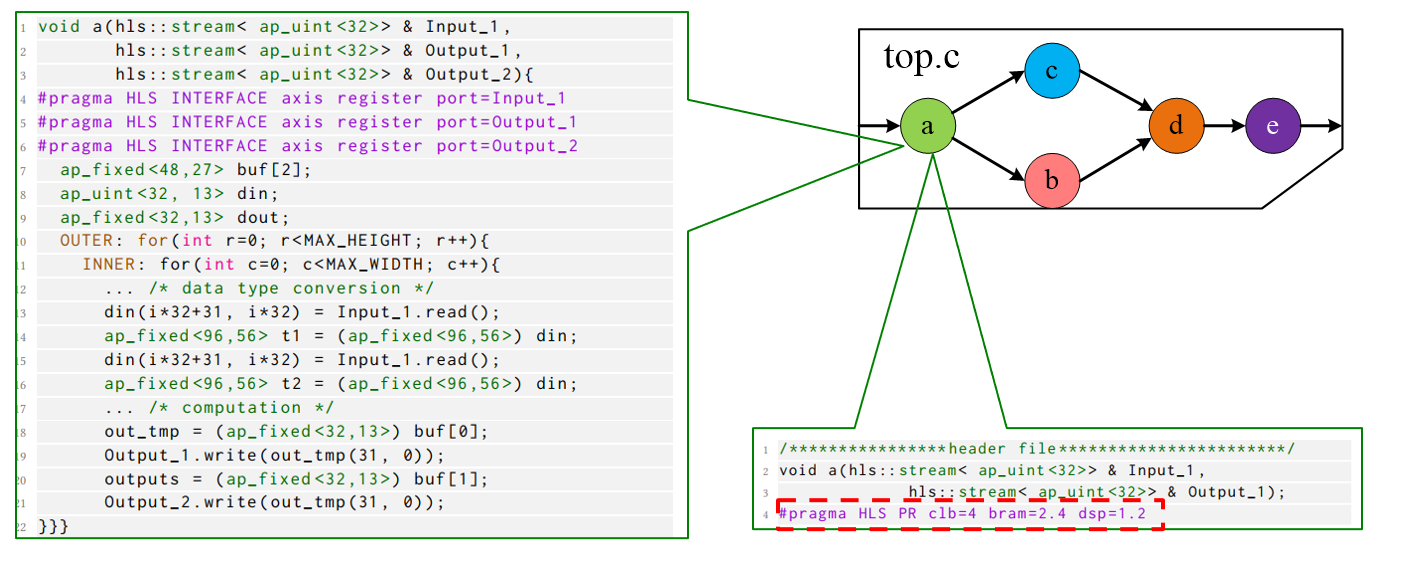
HiPR Toolflow
Initial-Compile Flow (Overlay Generation)
When compiling the C-based application for the first time, HiPR separately compile the operators in parallel. The PragmaParse can parse the top.cpp to extrac the interconnect information. The Floorplanner interprets the post-synthesis reports, detects the PR-functions according to the PR pragmas in the operators’ header files, and generates the floorplan xdc constraints files. Next, the overlay can be placed and routed in a monolithic way.

Incremental-Compile Flow (Seperately and Parallel Compile)
If we modify one or more PR-functions later, HiPR can detect the modified files and only re-compile that modules in parallel.
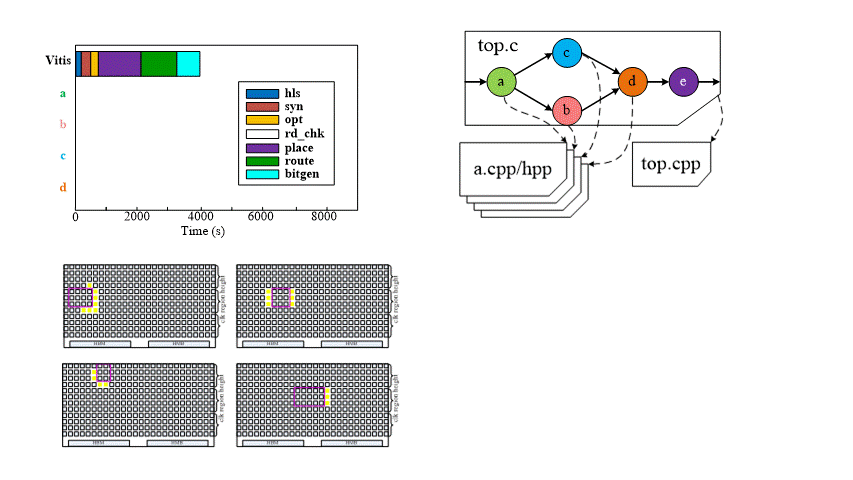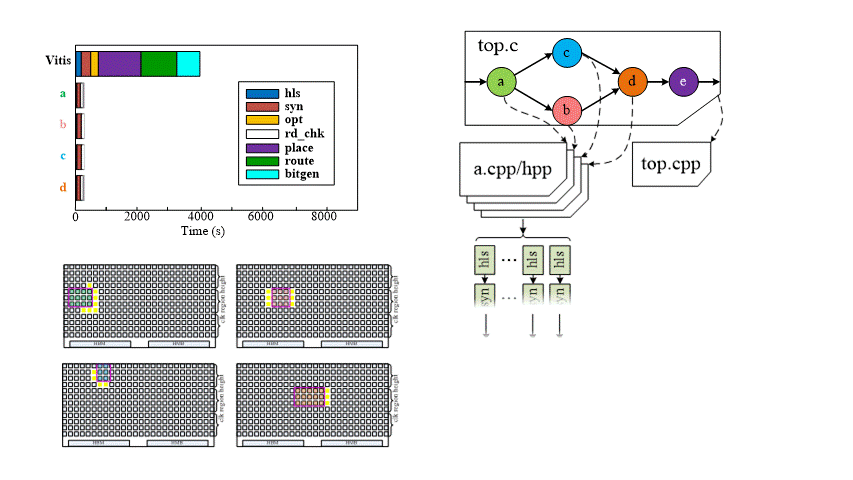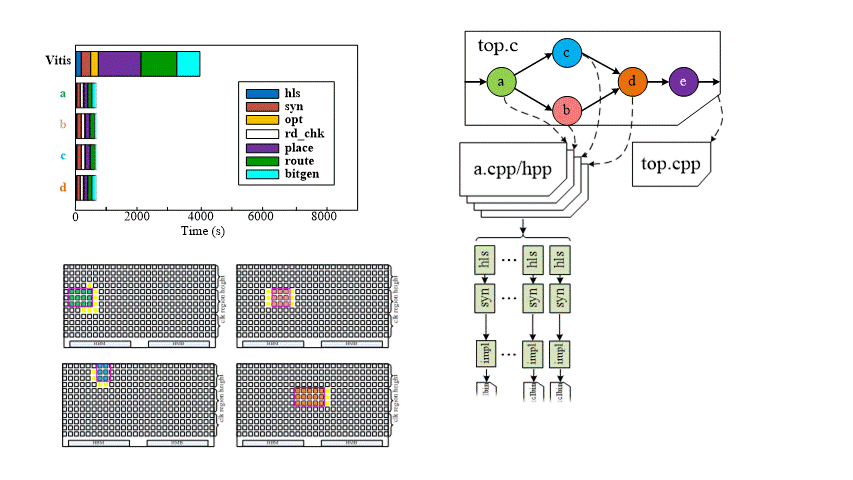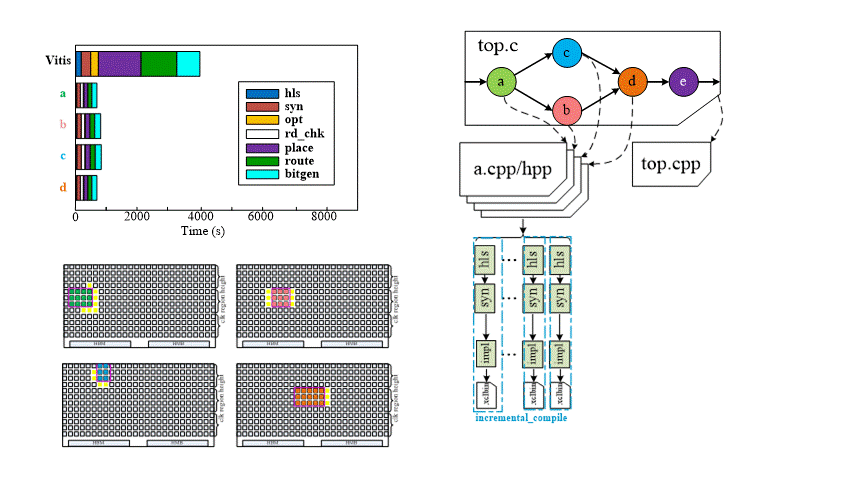
Evaluation on Alveo U50
Intial-Compile Time and Overhead
For the initial-compile, HiPR needs more time to set up the ovelay. We can see 15-67% compile time overhead.
| Benchmark names | Vitis / s | HiPR / s | HiPR Overhead |
|---|---|---|---|
| Rendering | 4264 | 7152 | 67 % |
| Digit Recognition | 5172 | 6125 | 19 % |
| Spam Filter | 3942 | 4541 | 15 % |
| Optical Flow | 4139 | 6880 | 66 % |
| Face Detection | 6288 | 8851 | 40 % |
| BNN | 6584 | 9632 | 46 % |
Intial-Compile Time and Overhead
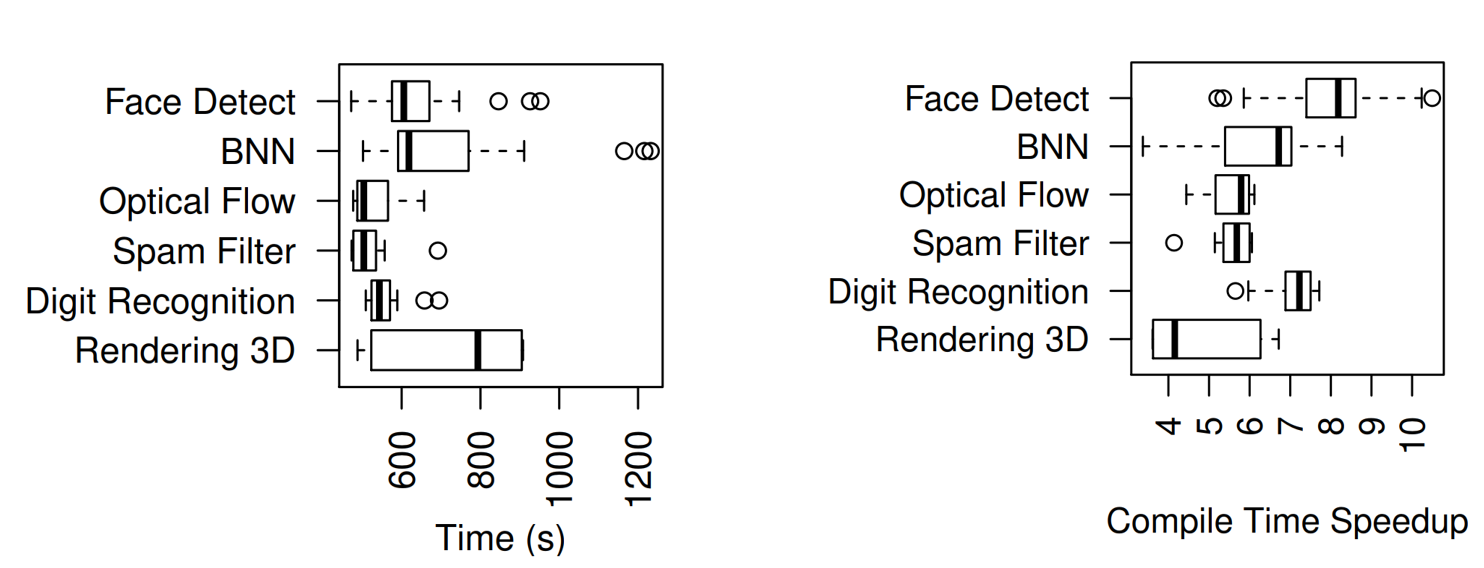
We use the worst case for each benchmark, as each benchmark may have several PR-functions. For the incremental-compile, HiPR can outperform Xilinx Vitis by 3.4-5.6X.
| Benchmark names | Vitis / s | HiPR / s | HiPR Speedup |
|---|---|---|---|
| Rendering | 3278 | 908 | 3.6X |
| Digit Recognition | 3927 | 695 | 5.6X |
| Spam Filter | 2865 | 692 | 4.1X |
| Optical Flow | 2918 | 657 | 4.4X |
| Face Detection | 4954 | 952 | 5.2X |
| BNN | 4154 | 1232 | 3.4X |
For the compile time distribution for all the operators for all the benchmark, we can see the compile accleration can be up to 10.5X.
Conclusion
HiPR enables the users to define Partial Reconfigurable (PR) functions at the C-level instead of Verilog modules. The automation from C-to-bitstream can save manual interference. The incremental-compile time can be accelerated by 3.4-10.5X.